The tweet below from @TrumpSc sparked a bit of a discussion about the AI involved in this Marvel Snap location, and I’d thought I would list some of the most common techniques to implement AIs for card/board games.
Ego is a random location that take over for the player, playing cards for them, making the current game a bit of a brain teaser.
How do you anticipate what Ego will play ? When do you retreat ? When do you double down with a snap ?
It’s the same mechanic players can willingly activate in their deck by adding Agatha Harkness.

Ego/Agatha seem to use, at the moment, the most basic way of doing an AI, and the first I’m gonna explain :
Random Valid Play
This AI type is really simple and goes like this :
- Filter out your invalid possibilities.
- Play one at random.
- Repeat until you have no more valid possibilities.
To take an example, in Marvel Snap you can play a number of cards each turn that must follow the Energy Rule. The cost of cards played must be inferior or equal to your total energy.
So if I am in turn 3, with 3 energy, I can only play any combination of 1,2 and 3 cost cards, as long as the total doesn’t exceed 3.
With a hand of cards(cost) : A(1), B(1), C(2), D(3), E(5), and the algorithm above the AI on turn 3 could play randomly:
- D
- C and A
- C and B
- A and B
The AI also must chose a valid spot to play the cards.
In Marvel Snap you have 4 spots per location ( so 12 total ) and some location effects could prevent you from playing certain cards, like the Crimson Cosmos.

Again the algorithm here is pretty simple :
- Filter out invalid spots ( card already there, location rule, etc. )
- Play a card in a remaining valid spot.
Of course, for clarity purpose, I’ve split it in two for cards and spots, but in reality the number of remaining spots, and what cards can be played there will impact the actual play so the actual algorithm should be a bit more complicated :
- Filter cards for max energy
- For each valid card, compute the possible list of spots.
- If there is at least one valid spot, play the card
- Filter cards for remaining energy
- Repeat step 2 until you can’t play anymore cards.
Pros and cons of the Random Play AI :
- Super easy to implement
- Super light performance-wise
- Super Dumb. Randomness is,well, random, so bad plays will occur often.
The “simulate a player” AI
One other quick way of writing a board game AI is to use the naive approach and code the decision process in order to simulate how a player would think.
There is no real algorithm for this because each game has unique rules and strategies, but common AI-Game frameworks like decision trees could be used.
Maybe in the game a good move is to play your biggest cards first ? Or last ? Then you implement just that.
Pros and cons of the “Simulate a player mind” AI :
- Easy to hard to implement, depends on how many rules and strategies you actually need to add.
- Light to heavy performance-wise, again depending on the numbers of computation you need to do.
- Your AI will be only as good as the person implementing it.
That last disadvantage is the real reason I wanted to talk about those kind of AIs, as they require the implementers to really be good at the game to be effective, and coding the strategies can quickly become a nightmare for any game with a bit of depth.
Imagine having to implement all of the different ways you think about a game as complex as Marvels Snap, with dozens of effects, hundreds of cards, and locations. Plays, counter plays, how to adapt to the opponent deck archetype and so on.
That’s why most AIs have game-agnostic algorithms, meaning they can apply to any game as long as you provide the rules and a way to evaluate if you are winning or losing.
Let’s talk about the first one :
Min iMax AI
Wikipedia page for reference HERE.
Minimax algorithm basically goes like this :
- Compute all possible plays for you
- For each play, look at the board state, and evaluate it to give it a score.
- Compute all possible plays for your opponent
- For each of your opponent play, look at the board state and give it a score.
- Compute all possible plays for your opponent
- Repeat until you have reached a desired depth ahead or the game is over.
- For each play, look at the board state, and evaluate it to give it a score.
- Then starting with the deepest possibilities, if it’s your turn to play propagate back the highest score you find ( because you assume you want the best possible move for you ) and the lowest score if that’s your opponent turn ( because you assume they will play their best move too )
- Once everything is propagated, you end up with the best of the max and min scores in all branches ( hence the MiniMax name ) and you take the move that lead you there.
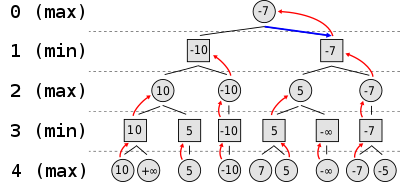
What the algorithm does is basically evaluate EVERY possible move combination for you and your opponent, [N] turns ahead in the future, and then use neat tricks to chose the best branch.
Pros and cons of the “MiniMax” AI :
- Easy to implement, known algorithm.
- No knowledge of the strategies involved as it will “brute force” all possible moves.
- Very computationally heavy, will impact time to solve or performances.
- Uncertainty after the max depth is reached.
- You need a good scoring, which requires knowledge of the game.
A few more points about the downsides.
Performances :
Let’s say you are implementing a Marvel Snap Minimax AI. How many board states do you have to calculate only one turn ahead ?
Well, you know your deck, so when you have to calculate your plays you can use your hand and deck to reduce the number of possible cards, so that’s good.
Let’s say you can play 1 card because you have a 1 cost card, so that’s 3 possibility because you have 3 locations to play it, and then you could pass. So your total possibilities is 3 + 1 = 4.
Then the same turn, your opponent could play nothing, or any 1 cost in the game, that’s 28, at each location, so 1 + 3*28 for them = 85.
All possible first turn states when bothers have played = 4 * 85 = 340 possibilities.
Just for turn 1.
Now for turn two, you take each of these 350 possibility and you calculate each possible turn 2 possibilities, which will be something like 4 for you depending on your hand then any combination of 1 costs and then 2 costs for the other player, so 4 * (1 + 27 * 26 + 43) = 4* 746 = 2984.
Turn 2 is 340 * 2984= 1 014 560 possibilities.
You can imagine that trying to guess turn 6 will likely be hundreds of billions of possibilities, taking up a huge amount of time and ressources to compute.
This algorithm has been improved over the years with neat mathematical tricks, like the alpha-beta pruning, that makes it easier to skip over entire parts of the tree of possibilities.
And of course it’s possible to “cheat” with your own game-specifics tricks.
For instance, in the above example, we assumed that the opposing player could play any cards in the entire card set, but we could reduce drastically that number by giving the AI the actual player deck. Turn 2 possibilities would then shrink from above 1 millions to a few hundreds. That change would improve the number of computations a lot, but would make the AI way better as it has access to information it should not have, the other player deck.
So you’ll have to counter balance that to make it somehow a bit dumber, most likely in the scoring.
Depth horizon :
Because of the number of computation that algorithm needs to make, it’s usually given a max depth as a number of turns in the future to compute. This gives the AI a blind spot that very good players can exploit. If the AI can read 4 turns in the future, but the player anticipate 5 turns ahead, it can lead the AI to paths where an upset or a counter can occur.
This changes a bit at the end stage of the game, where the max depth reaches only victories or defeat. The AI doesn’t have any blind spot anymore and so can play optimally until the end, but it might be too late if it has been led to a path where only defeat is waiting.
Scoring :
The beauty of the minimax is that it’s completely game agnostic except for the scoring of a game state.
That’s the heart of the algorithm and can make it really really good, or… not so great.
So you still need to find a good way to evaluate if you are in a good position to win or not.
In Marvel Snap that could be just checking the current location scores difference between you and the other players, and if you actually win two locations.

In games like Reversi, it’s well known that controlling corners is a very powerful move, as it can never be taken back by the opponent, so you can weight possibilities that gives you corners a higher score, and so on.
And last but not least, for probabilities lovers :
The MonteCarlo AI
Wikipedia HERE.
The name, again, comes from the algorithm used, and this one is fun as it, in theory, doesn’t require any knowledge of what makes a play good, only the rules and victory condition of the game. It’s a general purpose algorithm that can be use in games but also in any field that need to do a lot of simulations ( chemistry, electro dynamics, high frequency trading, etc).
It goes something like this :
- Compute all possible plays for you
- Play one randomly
- Compute all possible plays for your opponent
- Opponent plays randomly.
- Compute all possible plays for your opponent
- Repeat random plays until the game is over.
- Then repeat whole random games [N] times or for a fixed duration.
- Play one randomly
- Take the move that gives you the best probability of winning.

So basically you play lots and lots and lots of random games and calculate your win probabilities, until its statically significant, and then play the move that makes you win the most often because it has the highest win rate.
( Of course the actual algorithm is a bit more complicated and has various phases and optimizations with names likes selection, expansion and back propagation.)
Pros and cons of the “MonteCarlo” AIs :
- Easy to implement, known algorithm.
- No knowledge of the strategies involved as it will eventually “brute force” all possible moves.
- Computationally heavy, but you can stop whenever you want as long as you have run a good number of game simulations.
- Uncertainty if you don’t explore enough possibilities.
This algorithm is basically the inverse of the MiniMax. Instead of exploring all possibilities but stop at a certain depth, making your exploration of the possibilities very wide but not very deep, you go to the end game each time, but it takes time to explore everything, making it very deep but not very wide.
That means that an AI will actually get better if you run the algorithm for 10 seconds instead of 5 because it will have explored twice as many possible paths.
Another good thing about it is that you can easily stop and restart it, improving on what you already simulated ( even if each played move can throw away a huge number of simulations ).
Again there are neat tips and tricks to improve the MonteCarlo Algorithm by choosing which moves to explore first instead of being totally random, because you don’t really want to explore obvious bad moves. This usually involve knowledge of the game like in the MiniMax where you need to score each possible move to explore those that have a higher score first, or the inverse, explore paths that have never been taken to ensure no obvious blind spot is left.
Conclusion
I hope you enjoyed learning a bit more about card game AIs, though it’s obviously not exhaustive and there are many more techniques and algorithms that can be used.
Most really shine with 2 players games, but they can be adapted to handle more players, or even teams, that usually mean just more computations.